Mobile navigation menu

Effective Document Capture: Reduce Costs with Technology
Business process workflow experts have been writing for some time about the value of implementing an effective document capture strategy. To take advantage of that value, especially for cost containment, it is important to keep in mind that converting documents from physical to electronic format is a science.
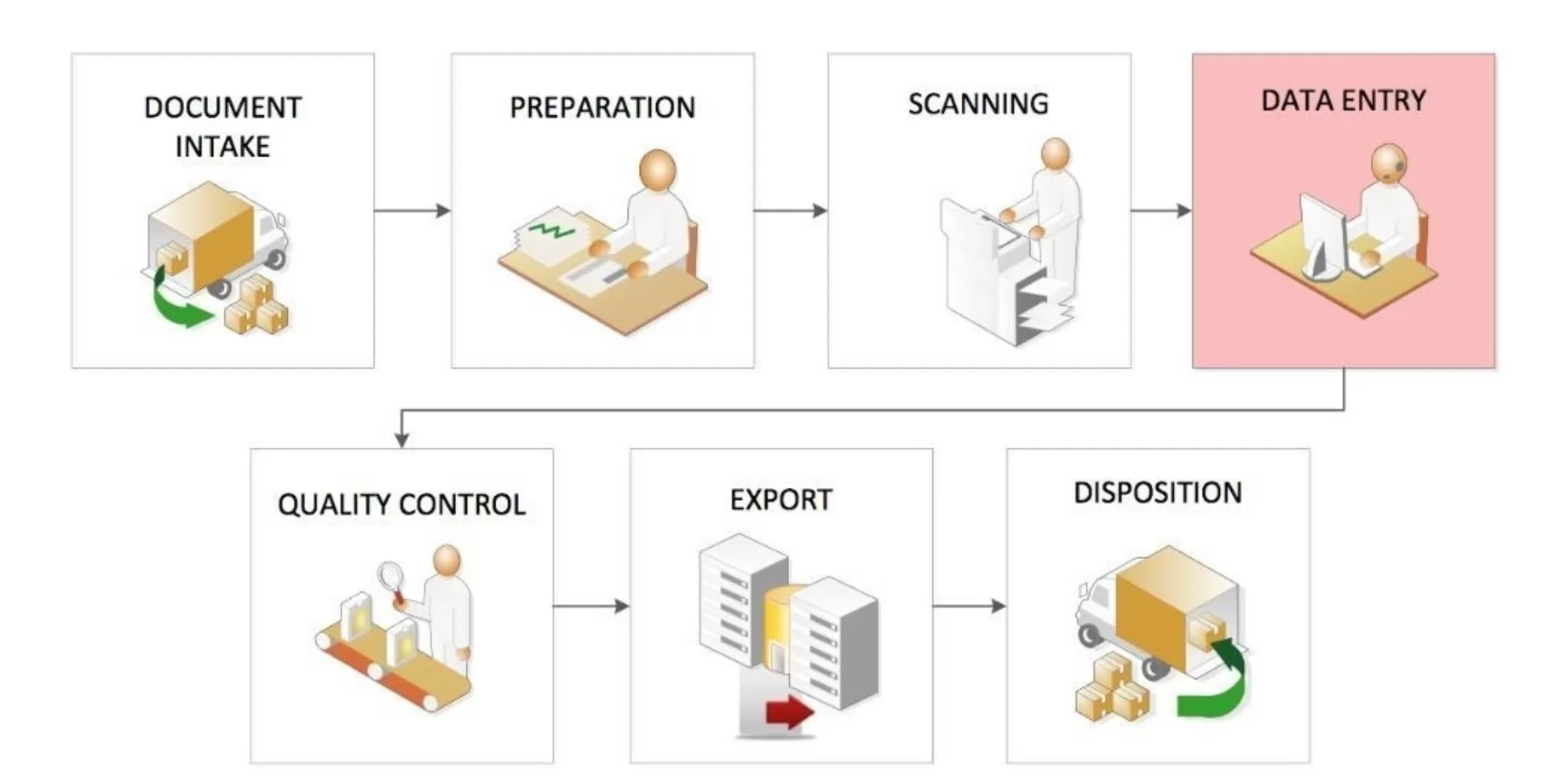
While the production workflow from a high level is basic in nature, the nuances that are involved in each step can vary significantly. A basic conversion workflow, as illustrated below, is comprised of document intake, preparation, scan, data entry, quality control, export and disposition. How each step is constructed can have dramatic implications on the cost of the overall project. In particular, the data entry process can be designed using either manual data entry or OCR (optical character recognition) data extraction, and it is important to know when to use one versus the other. Fortunately, there are key indicators that our experts have identified. These indicators, which I will spotlight in this article, can help in determining which data capture methodology you should consider implementing in order to minimize cost while maintaining quality.
Document Conversion Workflow
Manual Data Entry
Let’s focus for a moment on manual data entry, which involves a human operator typing information from the document to establish index value(s). Nearly all capture platforms currently contain a split screen view, enabling the operator to see document images on one side of the computer screen and key information such as account number, date and dollar amount into the appropriately labeled index field on the other side of the screen.
People will make mistakes; a single pass or glance of data entry typically does not adequately note errors and ensure quality. For this reason an organization may leverage what is commonly referred to as a double-blind data entry approach. Double-blind data entry consists of a second human operator performing a second round of data entry on a document in addition to what the first person performed. Whenever a discrepancy occurs between the keyed information provided by two different operators, the variation is displayed to a double-blind data entry operator. This third person will then select the correct value of the two keyed quantities or re-key the value in the event both entries are incorrect. In our experience, the process will generate an expected quality score greater than 98.5 percent accuracy when implemented correctly as opposed to an accuracy rate of about 90 percent with a single-pass data entry process.
The Issue of Cost
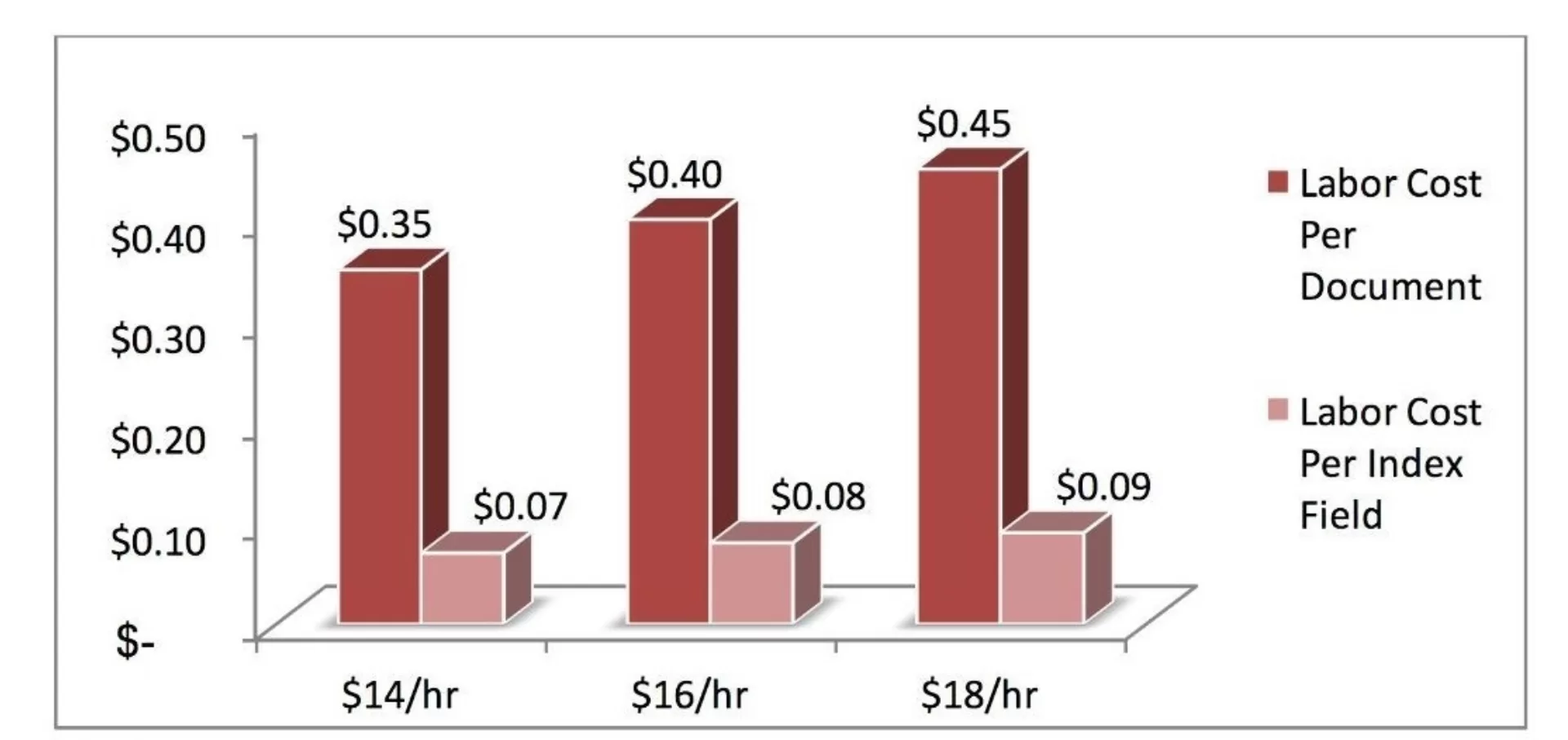
In order to evaluate the cost of data entry, we need to understand labor expenditure. Once again based on our experience, the typical data entry operator will perform an average of 4,500 keystrokes per hour. This takes into account such “down time” variables such as document load time and searching for values to type. If the requirements are to capture five index fields for each document, and the average length of each field is 10 characters, the operator will achieve a rate of 90 documents per hour during a single pass. When we take into account the time to evaluate discrepancies during double-blind data entry, that productivity number is reduced by 20 percent to 72 documents per hour. Assuming labor costs of $14, $16, or $18 per hour per data entry operator, we can build a labor cost model as seen in the chart below.
Leveraging OCR
When it comes to leveraging OCR there are many applications available that can be “trained” to extract text from an image to populate index values. While the technology has dramatically evolved over the past decade, to this day there is no application that is 100 percent accurate in automatic data identification and data extraction. So, how do we know when it becomes cost advantageous to leverage OCR technology as opposed to manual data entry? In order to answer this question, we need to establish a baseline labor cost for:
- Data entry (as was calculated earlier)
- Baseline labor cost for data validation (correcting OCR extracted index values)
- Manual review (providing a final review or audit of index values, post data validation)
To calculate the manual labor associated with generating OCR extracted data, I will use the following parameters:
- 50 percent of extracted data will be correct and have a high enough confidence level that data validation will not be necessary.
- 35 percent of extracted data will require the correction of an average of 10 characters per document (20 percent of all characters).
- 15 percent of index values will not be extracted and need to be hand-keyed during the data validation process step.
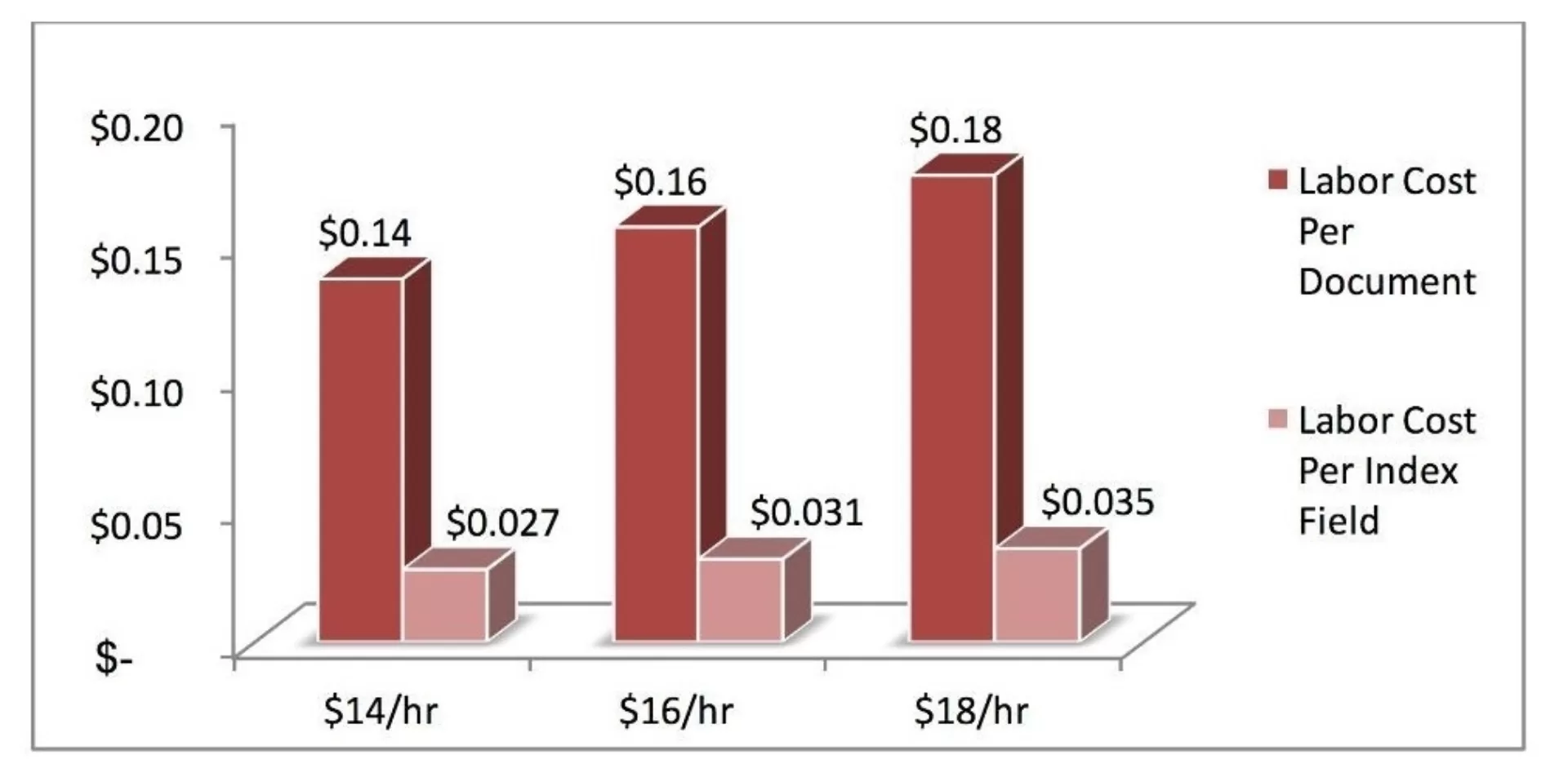
These parameters, which based on our research are in line with industry averages for semi-unstructured to unstructured documents, allow us to assume a throughput rate of 180 documents per hour for data validation and 240 documents per hour for final review. Using the same labor rates from the manual data entry exercise, we can generate the table as shown below.
The Threshold for Implementing OCR
Using OCR technology to perform document indexing can be an effective tool in reducing overall project cost. However, to ensure an adequate return on investment, software costs must be taken into account. The threshold for implementing OCR technology to reduce project cost will ultimately be driven by two key factors:
- number of index fields to be captured (fields per document]
- cost to deploy OCR technology (cost per document)
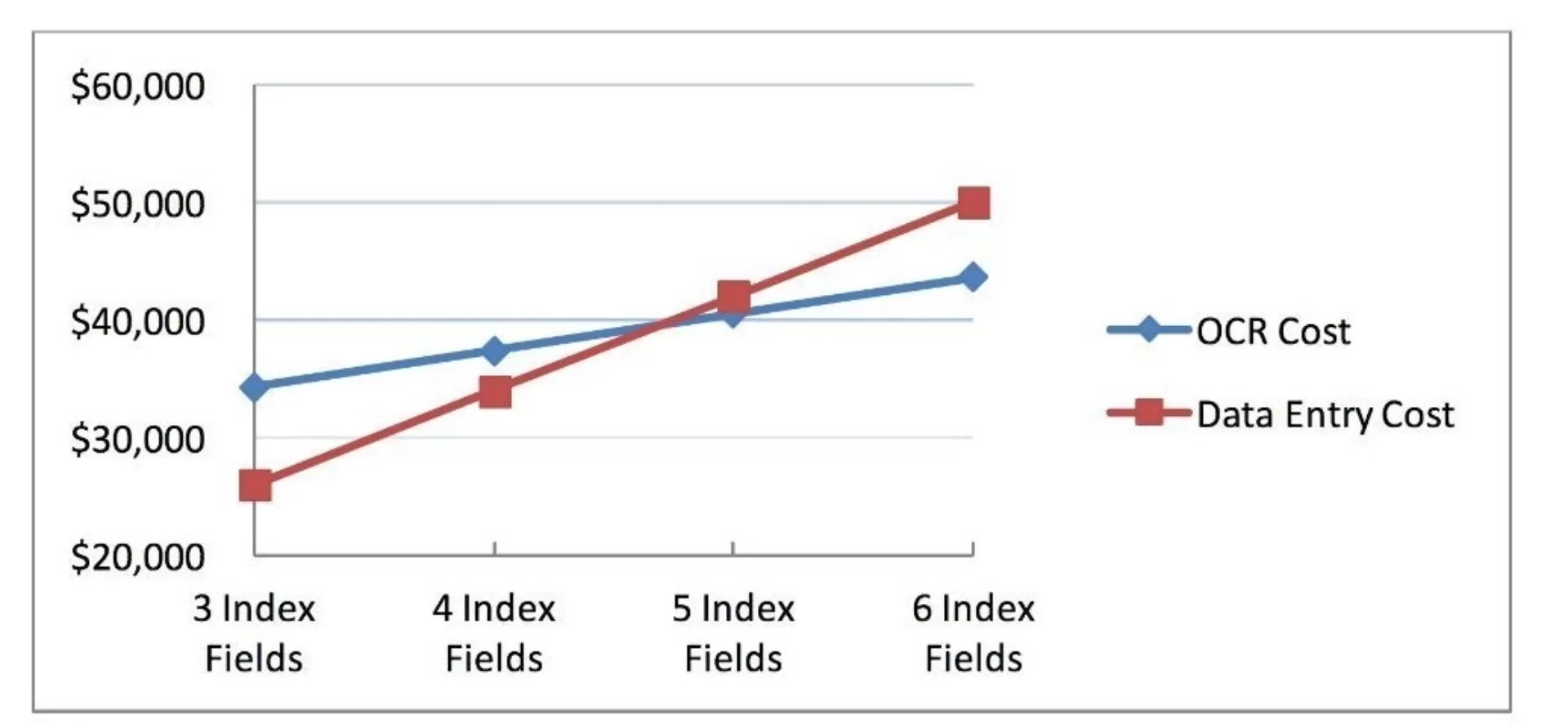
The chart below provides a model of how to determine the threshold for implementing OCR technology. For this example I applied a technology cost of $0.25 per document for OCR and a technology cost of $.02 for manual data entry. Assuming a project set of 100,000 documents, we can see that our threshold for implementing OCR would occur when the project requires five or more index fields per document to be captured.
Weighing the use of advanced technology is a very important part of document conversion, particularly since technology may not be the key element in all solutions. Working with clients to solve these challenges, the best managed services providers strive to uncover every opportunity to reduce costs without compromising quality. This includes passing the savings on to clients so they can benefit from streamlined workflows, reduced operational costs and gain confidence through knowing that no stone has been left unturned.
By Reza Pazuki, Solutions Engineer, Canon Business Process Services
Published in Workflow Magazine, December 13, 2016
Reprinted with permission.
Related Resources



